IFT6266 Final project: conditional image generation
Table of Contents
1 Introduction
This post is the final report for my implementation of the conditional image generation project 1, in which the task is to generate the 32x32 center of a 64x64 RGB image, given the border and a caption.
The post begins with a discussion of the models I considered for the task, followed by a presentation of the actual code implementation. Results are then discussed before concluding.
My previous blog posts for this projects can be found here, while the git repository containing the code can be browsed here.
2 Conditional image generation
Let \(x\) be a 3D tensor representing an image, with element \(x_{i,j,k}\) reprensenting the pixel in row \(j\) and column \(k\), in channel \(i\). For this task, we will assume that there are 3 channels and that the images are 64 by 64. Let \(x^{(c)}\) be the 32x32 center patch of the image \(x\), and \(x^{(b)}\) be the border around it.
2.1 Densely connected neural networks
In the first proposed model familly, the formal problem we have to solve is to find a fixed mapping \(f: x^{(b)} \to x^{(c)}\). This task can be tackled with a parametric approach, namely, finding the best parameter set \(\theta\) in \(f(x^{(b)};\theta) = \hat{x}^{(c)}\).
We will define \(f(x^{(b);\theta})\) to be a densely connected, multi-layer neural network (note that this means that the input image \(x\) has to be flattened into a vector). The basic building block of this model is an affine transformation which is then non-linearly transformed through a rectified linear unit:
\begin{equation} Y = max(0, XW + b) \end{equation}where \(X\) is the design matrix containing one example per row and \(W\) and \(b\) are the parameters of the transformation. These layers can be chained sequentially:
\begin{equation} Y^{(i+1)} = max(0, Y^{(i)}W^{(i)} + b^{(i)}) \end{equation}Where \(Y^{0} \equiv X\). At the output layer, a element-wise sigmoid activation will be used:
\begin{equation} \sigma(x) = \frac{1}{1 + e^{-x}} \end{equation}which constrain the generated pixel values to be between 0 and 1. They can then be scaled by 255 to yield a valid image.
The weights can then be iteratively updated by making small steps in the direction opposite to the gradient of a loss function. This loss function will either be the squared error:
\begin{equation} SE = (x^{(c)} - \hat{x}^{(c)})^{2} \end{equation}If we view each pixel's output as a probability of being activated in a particular channel, then a natural loss function is the sum of the pixel-wise binary crossentropy:
\begin{equation} XE = - \sum_{i,j,k} (x_{i,j,k}^{(c)}log(\hat{x}^{(c)}_{i,j,k}) + (1 - x_{i,j,k}^{(c)})log(1 - \hat{x}^{(c)}_{i,j,k}) ) \end{equation}To prevent overfitting, a term penalizing large weights is added to the loss
\begin{equation} L_{W} = \alpha W^{T}W \end{equation}During training, the distribution from a layer's output change as the weights of this layer are updated. This problem, refered to as the internal covariate shift , complicates the learning task of the downstream layers. This can be mitigated by using batch normalization 2, a technique in which the input of a layer is normalized as a function of the mean and variance of the inputs in a mini-batch:
\begin{equation} y = \gamma \frac{x - \mu}{\sqrt{\sigma^{2} + \delta}} + \beta \end{equation}Where γ and β are learned parameters and δ is a small constant added for numerical stability.
For the gradient descent, two different momentum schemes are considered. First, the "vanilla" momentum:
\begin{eqnarray} g = \nabla_{\theta} L(x^{(c)}, \hat{x}^{(c)}, \theta) \\ v = \alpha v - \epsilon g \\ \theta = \theta + v \end{eqnarray}Where α and ε are fixed constants. The ADAM algorithm is also considered:
\begin{eqnarray} g = \nabla_{\theta} L(x^{(c)}, \hat{x}^{(c)}, \theta) \\ r = \rho_{1}r + (1 - \rho_{1})g \\ s = \rho_{2}s + (1 - \rho_{2})g\odot g \\ \tilde{r} = \frac{r}{1 - \rho_{1}^{t}} \\ \tilde{s} = \frac{s}{1 - \rho_{2}^{t}} \\ \theta = \theta - \epsilon \frac{\tilde{r}}{\sqrt{\tilde{s} + \delta}} \end{eqnarray}2.2 Deep convolutional generative adversarial networks
In the second familly of models considered, the goal is to model the probability distribution \(P(x^{(c)}|x^{(b)})\). This is achieved via a generator network, \(G(x^{(b)}| z)\) where the vector \(z \sim U(0, 1)\).
One effective way of training the generator is by using an auxiliary discriminator network 3, which learns a mapping \(D(x^{(c)}|x^{(b)}) = p\), where \(p\) is the probability that \(x^{(c)}\) comes from the data distribution. The two networks are then trained in tandem using the same techniques described above. The discriminator loss is the binary cross-entropy where the positive examples are drawn from the data distribution and the negative from the generator:
\begin{equation} LD = - log(D(x^{(c)}|x^{(b)}) - log(1 - D(G(x^{(b)}, z)|x^{(b)})) \end{equation}The generator is trained to fool the discriminator:
\begin{equation} LG = - D(G(x^{(b)}, z)|x^{(b)}) \end{equation}The actual architecture of \(G\) and \(D\) follow the outline of the DCGAN paper 4, which make the following recommendation:
- Use convolutional instead of affine layers in G and D
- Use strided convolutions to upsample and downsample
- Use batch normalization in G and D
- Use ReLU hidden activations and a tanh output activation in G
- Use a leaky ReLU (a ReLU with a non-zero slope in the negative part) in D
In convolutional layers, the affine mapping is replaced by convolutions with kernels which are slided across the image to produce feature maps. By increasing the stride (the "step size" of the sliding of the kernels), the dimensionality of the feature maps can be reduced.
To incorporate the latent code \(z\) in the input to the generator, the length vector is projected by an affine map and reshaped to a 64x64 matrix, allowing it to be treated as a regular channel.
Also, instead of feeding only the border to the generator, a complete image is used where the center is the output of a model from the first familly described above:
\begin{eqnarray} \tilde{G} \equiv \tilde{G}(x^{(b)}, f(x^{(b)}) = \hat{x}^{(c)}_{(0)}, z) \end{eqnarray}3 Code
The code discussed in this section can be browsed here, and corresponds to the "final" tag. Myself being a Keras user, I've decided to write everything in straight theano in order to learn a bit more about implementation details. This ended-up being much more work than I initialy had foreseen (the network.py file has over 1k SLOC), but I did learn a lot about the lower-level details and it made me appreciate how worthwile are the higher-level APIs provided by libraries like keras.
This section starts with a presentation of the layer API and the different implementations. The network class, which wraps a collection of layers and provides the training logic is then described along with a specific function for generative adversarial training. I then discuss some small toy problems used to validate the implementation.
3.1 Layers
3.1.1 API
The interface that a layer must implement is defined by 7 methods:
-
Layer.expression(self, X) - The symbolic theano expression defining the layer
-
Layer.training_expression(self, X) - In some cases, the expression is not the same at training and test time (e.g. dropout)
-
Layer.parameters(self) - The list of trainable parameters
-
Layer.reg_loss(self) - Auxilliary term to add to the global loss. This is used to implement weight norm penalties.
-
Layer.updates(self) - List of
(variable, update)tuples defining auxilliary update operations besides the gradient descent. Used, e.g. to compute the online mean in BatchNorm layers. -
Layer.save(self, h5grp) - Function used to save the layer configuration and parameters.
-
Layer.load(h5grp) - Static method used to load a saved layer.
With this API, several layers were defined:
-
Generator - Created at the last minute to ease the task of writting the conditional GAN. Its expression takes as input a 64x64 image and outputs this image and a length-100 latent vector that is mapped by an affine transformation to a 4th channel.
-
LSTM - long-short-term-memory recurrent layer. It is actually
super slow and I didn't have enough time to debug this so
I unfortunatly could not use it. It definitely made me
realize the huge amout of paramters these networks have
though! And, it provided an excuse to finally learn how to use
theano.scan. -
Recurrent - A simple recurrent layer. Much simpler than the LSTM but much less powerfull.
-
Convolution - The standard convolutional layer. The border mode and strides can be specified and there is also an option of including L2 loss on the kernel.
-
MaxPool - Pooling by maximum value. Used to reduce the dimensions of the convolved feature maps.
-
Dropout - The dropout regularization layer. At training time, a binary variable is sampled for each input from a Bernouilli distribution and is multiplied to the corresponding input. At test time, the input is scaled by the inclusion probability (equivalent to multiply the weights of a downstream affine transformation layer)
-
ScaleOffset - scale and offset the input by fixed constants.
-
Clip - Constrain the input to be within a fixed range.
-
LinearTransformation - This is actually the affine transformation but I never bothered setting the name right!
-
ReLU - The rectified linear unit activation. It takes an optional
alphaparameter defining the slope of the negative part. If this parameter is set at a different value than its default of zero, it yields the leaky ReLU. -
Tanh - hyperbolic tangent activation
-
Sigmoid - Sigmoid activation
-
Softmax - Softmax activation
-
BatchNorm - The batch normalization layer, with a special setup if using to normalized convolved feature maps.
3.2 Network class
The network class is a sequential collection of layers defining a
model. The most interesting bits are probably the __cache_generator
function, which allows a number of mini-batches of data to be cached
in shared variables to eliminate the memory bottleneck, especially
when running on the GPU, and (especially) the
__make_training_function method, which actually implements SGD with momentum
and the ADAM algorithm.
3.3 GAN training
There is a function, train_GAN, which take as input two compiled
Network objects and train them with the GAN framework. The data and
the latent code is passed by defining python generators from which the
function sample batches.
3.4 Validation
Since I was starting from scratch, I needed a couple of simple toy problems to validate my layers.
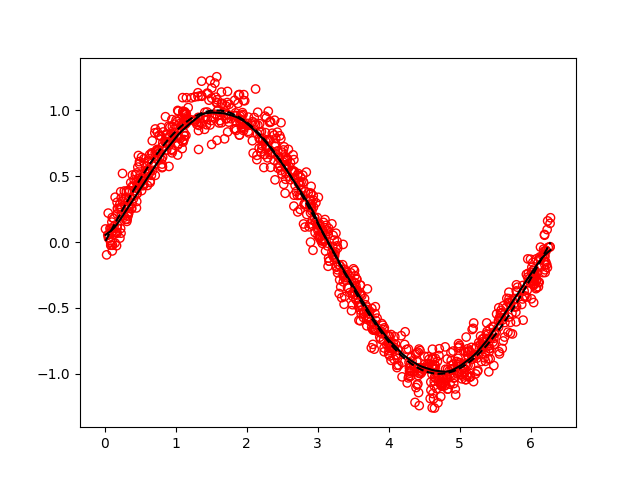
All of the dense layers were tested on the simple problem of fitting a
noisy sine function, with satisfactory results:
The convolutional layers were tested with an implementation of LeNet5 on the MNIST dataset:
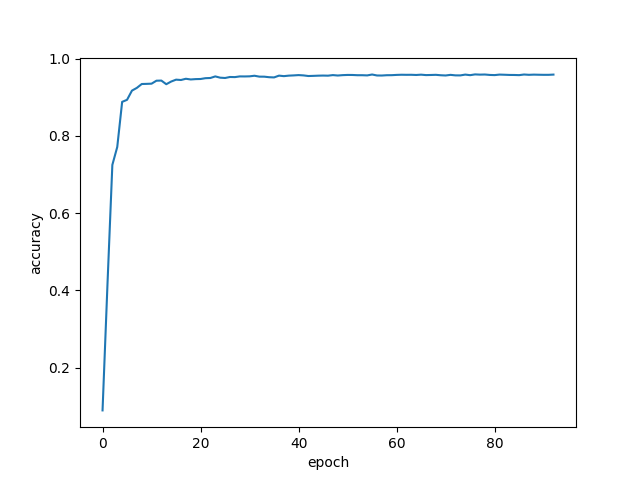
Figure 1: Accuracy vs training epochs
The recurrent layers were tested on a classification task between two 2D gaussian clusters, where the inputs are a variable number of sampling from a given cluster.
The GAN training function was tested on a generation task where the targeted distribution is a simple 2D normal distribution.
4 Results
I will now describe the results I've got. Before I jump into this though, a few words about what didn't work.
As said earlier, my LSTM implementation has a speed bottleneck somewhere and I did not have time to debug it, rendering it unusable to produce embeddings from the caption. I've also found that the simple recurrent layer was not really powerfull (given the limited hyperparameter tuning that I did), so unfortunatly I did not suceed in incorporating the captions in a working model.
After I had established a working baseline with a dense MLP, I tried to optimized some convolutional models, but could not get them to output anything other than a grey patch. Looking at the blogs, though, it looked like students fiddling with conv -> deconv architectures were getting similar results to my baseline, and so I did not spend more time with these models.
What did seem to work, though, were generative adversarial networks. I
first started just plugging my dense MLPs into this framework but that
did not work very well, even following the GANHacks 5
recommendations. In the end, I ended up going down the obvious path of
implementing the DCGAN model 6. My implementation can be found in
good_models/model_13.py in the code repository. The big problem at
this step was that there wasn't a significant amount of time left and
so the training essentially had to work on the first try. After
spending some time carefully checking that everything ran fine (but
super slowly!) on the CPU, I optimistically submited some jobs on the
Hades GPU cluster. As per Murphy's law, the code crashed and no jobs
suceeded. I could not get it to reproduce on the CPU and didn't
succeed on debugging the GPU-related problem, and since the CPU
training was much too slow, I unfortunately don't have results for the
DCGAN :(
4.1 Metrics
The gold standard is manual inspection of the generated images, however I also looked into alternative metrics to quantify the quality of the generated image, which as we all know is an interesting problem in itself. We can see an image as a collection of pixels, which themselves can be viewed as instances of 256 different classes. In this view, it is possible to measure a probability distribution over pixel values for a given image. It is then possible to measure the Kullback-Liebler divergence (KL) between this distribution and another one. KL measures (in a sense) how much 2 probability distribution differs. We can choose to compare the distribution from the generated image with the true image, or the distribution from the border. As training progresses, this divergence goes down:
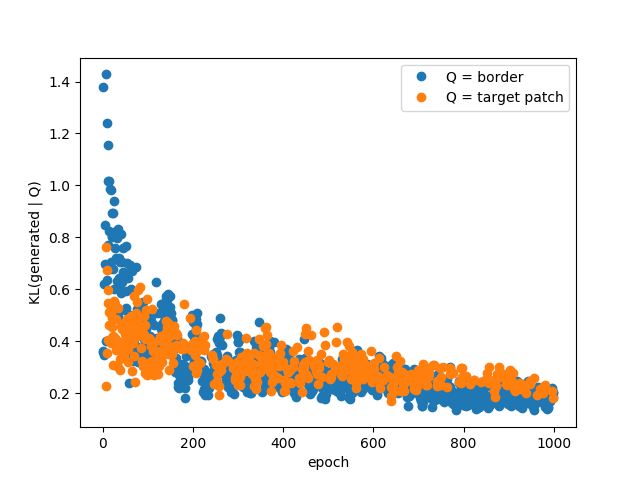
Figure 2: The K-L divergence between the border and center for one image, as training progresses.
This measure jumps around also, which suggest that smoothing might be necessary, but it actually seems to be a good indication of the fit quality. Surprisingly this works as well when comparing with the true center patch or with the border! Of course, minimizing this divergence only ensures that the pixels are sampled from the right distribution but it cannot quantify the structure in the images.
4.2 Generated images
I have three similar models which have what I deem to be acceptable results. The patches are quite blurry, but they contain the right structure (at least partially). The models are different configuration of a 3 hidden layer MLP with 1k hidden units per layer, with batchnorm at each layer and a sigmoid activation at the last layer. For the code, see goodmodels/model0{1,3,4}.py.
The first network is trained using SGD with momentum on a mean square error loss, using a very small learning rate (1e-7).

The second network is like the first one but using the ADAM algorithm with the default parameters.

The third one is like the second one, but the loss is a sum of the pixel-wise binary crossentropy. This effectively views each output as the probability that the given pixel in the given channel is fully activated.

These are relatively simple models, and so I'm pleasantly surprised that they work so well :)
5 Conclusion
While I'm a bit disappointed that I did not succeed in using the
captions and that I could not produce DCGAN results do to a
GPU-specific problem, I'm quite happy with what I've accomplished with
this project. After all, I do have models which perform relatively
well, and I must say I've learned a lot from having to implement every
functionality in straight theano! At the same time, this makes me
appreciate the T.grad function of theano, without which this would
have been very difficult, and it also made me realize how easy the
higher level APIs (e.g. Keras) make it to use deep learning.
Overall, this was a fun project and a good learning experience :)